Several times in a project I had to use regular expressions to match some pattern in a string. I started reading several tutorials but the regexes looked just too cryptic to me. Fortunately I always found the answer on Stackoverflow that either did exactly what I wanted or something similar that could be adapted easily. However last week again I had to use regular expressions and I needed many. It was time to get my feet wet and actually learn how to use them. I don’t know all the exceptions and details of every regex dialect. That is not what this article is about. It’s about the basics. Hopefully it is helpful for those who haven’t really started yet. So here it is…
Introduction
With a regular expression you can find patterns in a string. For instance you can find certain keywords in a text or you can find specific formatted pattern (like email addresses, phone numbers, or hex numbers) in a text.
A regular expression represents a state machine which is used to parse a text to find matches. For most programming languages there are regex engines that are able to use regular expressions and find matches in a text.
Developing and Testing Regexes
When I develop a regular expression I find it very helpful to draw the state machine of the regex. Check out this Website which does exactly that. By the way all regex statemachine diagrams below were generated by this regex tool.
To test a regex I use this very helpful regex test tool. You can enter the regex and the text and see immediately while you type where the matches are.
Literal Characters
Lets say the regex is “ca” and the text is “dog, car, cat”. The engine starts at the “d” of “dog” of the text to try to match the “ca” of the regex. It finds the first match at the “ca” of “car”. As the regex is finished it starts over and tries to match again the “ca” of the regex in the text continuing at the next character in the text. After the space it finds the next match at “ca” of “cat”. This was the last match so we are done having found 2 matches.
The state machine is very simple. It only has one state.
Escaping
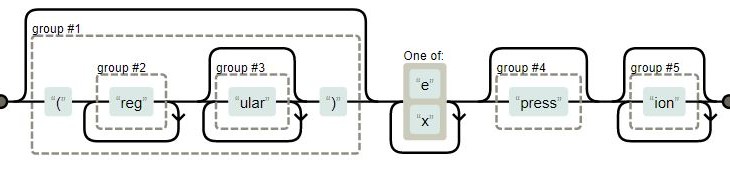
In the previous regex the characters we wanted to match “normal” letters. Lets consider we want to find “(” in a text. As “(” has a special meaning in regexes we need to escape it. So the regex is “\(“.
Quantifiers
There are symbols that define how many times the previous character (or group) must occur. * means the previous character must occur 0 or more times. For instance the regex “a*” matches “”, “a”, “aa”, …
The quantifier refers to the previous characcter (or group). “abc*” matches “ab”, “abc”, “abcc” …
| Regex | Statemachine | Description |
|---|---|---|
| “abc*” |
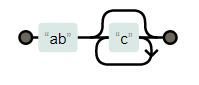
|
0 or more times |
Another quantifier is “+”. It means 1 or more times, ie. “abc+” matches “abc”, “abcc”, “abccc”, it does not match “ab”.
| Regex | Statemachine | Description |
|---|---|---|
| “abc+” |
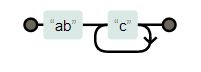
|
1 or more times |
“?” means 0 or 1 time, ie. “abc?” matches “ab” and “abc”.
| Regex | Statemachine | Description |
|---|---|---|
| “abc?” |
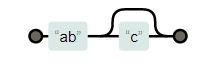
|
0 or 1 times |
“{}” indicates a minimum and maximum occurrence of the preceding character. “abc{3}” matches “abccc”
“abc{2,3}” matches “abcc” and “abccc”.
| Regex | Statemachine | Description |
|---|---|---|
| “abc{2,3}” |
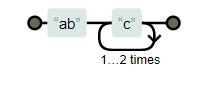
|
Min 2, max 3 times |
Character Groups
Character groups are written in square brakets []. The text matches to any of the characters in the group, ie. “[abc]” matches “a” or “b” or “c”.
The regex elements can be combined, see some examples in the table below.
| Regex | Statemachine | Description |
|---|---|---|
| “a[bc]+” |
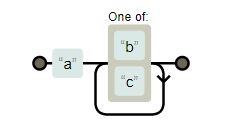
|
matches “ab”, “ac”, “abb”, “abc”, “acc”, “acb”,… “abbbcccbbc” … |
| “[a-f]” |
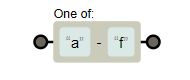
|
Character range matches “a”, “b”, “c”, “d”, “e” or “f”. |
| “[^a]” |

|
Negation matches any character but “a”. |
Grouping
In (…) you can group parts of characters together, see table below.
| Regex | Statemachine | Description |
|---|---|---|
| “(ab)*” |
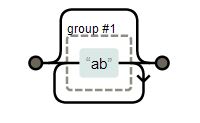
|
matches “”, “ab”, “abab”, .. |
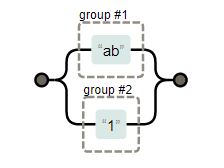
| “(ab)|(1)” |
|
matches to “ab” or “1”. |
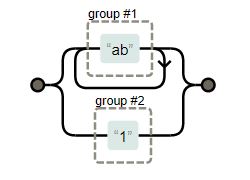
| “(ab)+|(1)” |
|
The grouping combined with quantifier. Example matches with “ab” 615-544-5408 , “abab”, “ababab”, “1”. |
Word Boundary
| Regex | Name | Description |
|---|---|---|
| “\b” | Wordboundary | Regex: “\bworld\b”, text: “hello world, helloworld”. Matches the word “world” but does not match “helloworld”. |
Example with Statemachine
Let the regex be “\b0x[0-9a-f]+\b” and the text “add(0x1ff0, var)”. The regex engine take the first part of the regex “\b” and starts to try to find a match in the text. At the beginning we have a word boundary so the match starts. The next part of the regex is “0x”. The text continues with “a” of “add” which is no match. So we are looking for a word boundary again. It finds the match after the braket. Here is a word boundary and it finds a match for the “0x”. It goes to the next character in the text “1” and the next part of the regex “[0-9a-f]” and checks if they match. They do. The next character in the text is “f”. The next part of the regex is a word boundary or another “[0-9a-f]”. The engine tries to find the longest match possible. The “f” matches. This goes on until there is a word boundary at the “,”. The regex ends. So the engine found “0x1ff0” and after that no other matches are found.
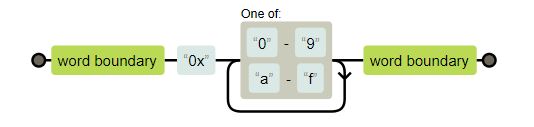
The point is the engine is processing the regex starting at the beginning of the regex then walks character by character through the text. If it finds a match it goes to the next character of the regex. If this regex-character does not match the text then the engine starts again at the beginning of the regex and continues at the place in the text where it left off.
Anchor
The regex “^abc” anchors the match to the start of the text. In other words: to match the text must start with “abc”.
The regex “abc$” anchors the match to the end of the text. In other words: to match the text must end with “abc”.
Shortcodes
Here are some often used shortcodes:
| Shortcode | Explicit From | Description |
|---|---|---|
| “\s” | “[\t\f\n\r ]” | whitespace |
| “\d” | “[0-9]” | digit |
| “\w” | “[AZ-a-z0-9_]” | wordcharacters |
| “\D” | “[^0-9]” | Anything but a digit (negation) |
| “\W” | “[^A-Za-z0-9_]” | Anything but a wordcharacter (negation) |
| “\S” | “[^\t\f\r\n ]” | Anything but whitespace (negation) |
Modifier
Modifiers change the meaning of the regex or parts of the regex.
In some regex dialects the modifier “m” is before or after the regex, ie “/regex/m” or “m/regex/”.
In .net modifiers can have a beginning and an ending, ie. “(?m)regex(?-m)regex_without_m”. The modifier applies to the regex part after (?m) and before (?-m). The (?-m) is optional. Often used modifiers are:
| Regex | Description |
|---|---|
| g | global (without g the first match only is returned. With g all matches returned. Second search is started where last match ended. No overlap) |
| i | case insensitive |
| m | multiline: This affects ^ and $. Now ^ and $ are used for each line of the input text instead of the complete text |
| s | Dotall or Singeleline: it affects “.” to match “\n”.) |
| x | Extended: whitespace is ignored, so you have the option to split up your regex on multiple lines and add comments using #. To add a space to the regex use “\20”, “\#” for actual # |
Pitfalls
Note that there are several different regex dialects and different engine implementations. Some features are even dependent upon your environment (locale). Check the manual of your engine for details.